Modern Data Platform Implementation
Turn Your Data Into a Competitive Advantage
Poor data quality costs enterprises $10-15M annually. Data scientists spend 80% of their time on preparation, not insights. And most organizations can't adopt AI because their data isn't ready. We solve all three. As a Databricks Partner, we implement unified lakehouse architectures with Unity Catalog governance—delivering production-ready data platforms in 60 days. Our clients see 40-50% cost reduction and build the AI-ready data foundation they need.
Our Approach
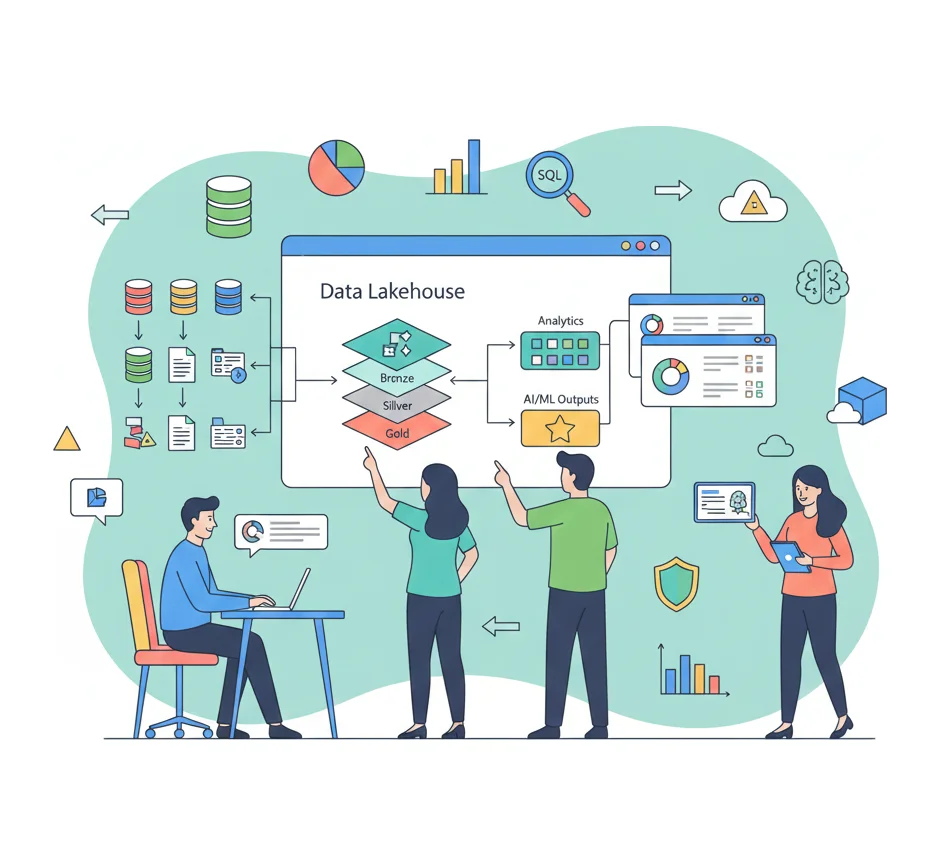
Platform Architecture & Strategy
Designing Your Modern Data Foundation
We design comprehensive data architectures that support your current needs and scale for future requirements:

- Lakehouse Architecture Design: Creating unified architectures that combine the best of data lakes and data warehouses with Delta Lake format.
- Business Value Alignment: Tying platform capabilities directly to business objectives and defining KPIs to measure success.
- Data Governance Framework: Implementing Unity Catalog with comprehensive lineage, access controls, and data discovery capabilities.
- FinOps & Cost Management Strategy: Designing for cost efficiency with clear visibility into resource usage and spending.
Databricks Platform Implementation
Building Your Unified Data Intelligence Engine
We implement and configure the Databricks Data Intelligence Platform to create a comprehensive data processing environment:

- Databricks Workspace Setup: Configuring optimized Databricks environments with proper cluster policies, security settings, and cost controls.
- Data Engineering Workflows: Implementing robust ETL/ELT pipelines using Delta Live Tables for automated data transformation and quality management.
- Unity Catalog Deployment: Setting up comprehensive data governance with fine-grained access controls, data lineage, and discovery capabilities.
- Accelerator Deployment: Implementing our pre-built accelerators for FinOps dashboards and automated governance to fast-track your time-to-value.
Data Engineering & Pipeline Development
Automating Data Workflows
We build robust, scalable data pipelines using Databricks-native technologies that ensure data quality and reliability:
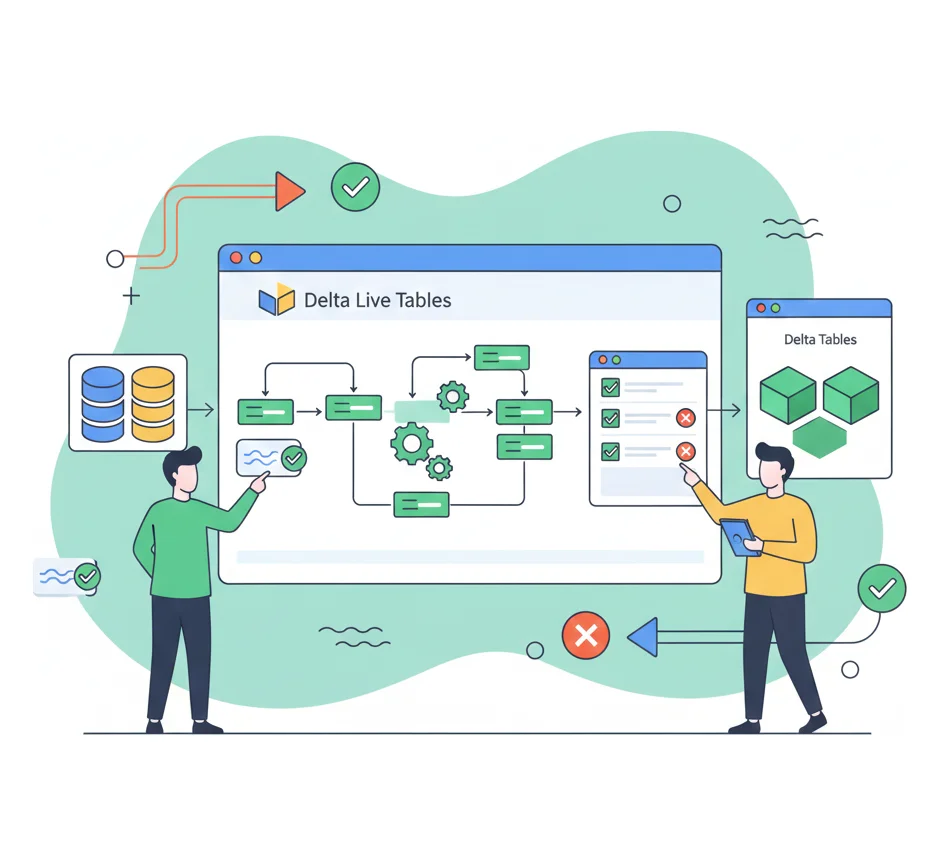
- Delta Live Tables: Creating declarative ETL pipelines with automatic data quality monitoring, lineage tracking, and error handling.
- Real-time Streaming: Implementing streaming analytics with Structured Streaming and Auto Loader for real-time insights and decision-making.
- Data Quality Framework: Building automated data quality checks, monitoring, and remediation processes using Delta Live Tables expectations.
- Medallion Architecture: Implementing bronze, silver, and gold data layers for progressive data refinement and quality improvement using Delta Lake.
Analytics & ML Enablement
Empowering Data-Driven Decision Making
We enable self-service analytics and machine learning capabilities across your organization using the complete Databricks platform:

- Databricks SQL & Warehouses: Enabling business users with serverless SQL warehouses and seamless integration with BI tools like Tableau, Power BI, and Looker.
- MLflow & Model Management: Implementing comprehensive ML lifecycle management with experiment tracking, model registry, and automated deployment pipelines.
- Feature Engineering: Setting up feature stores and collaborative data science environments with optimized compute and advanced analytics capabilities.
- Generative AI Enablement: Preparing the platform for advanced AI workloads including RAG applications, vector databases, and foundation model fine-tuning.
Methodologies and Tools
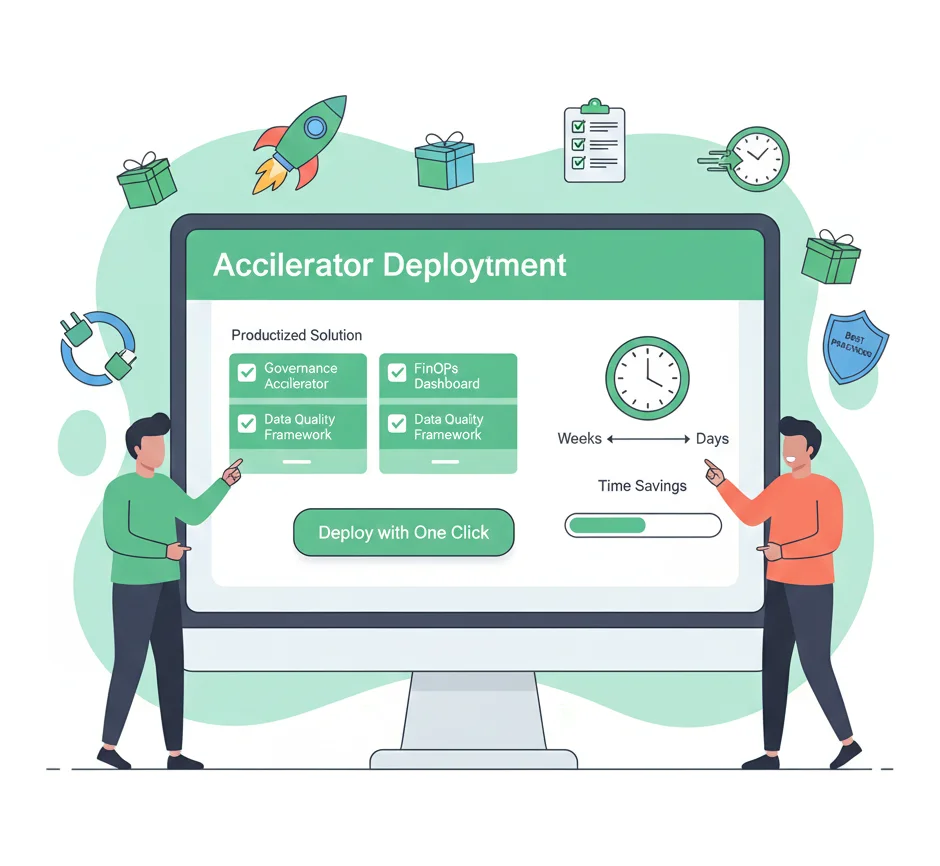
Proven Frameworks & Accelerators
Productized Expertise for Faster ROI
We productize our expertise into proven frameworks and accelerators that automate critical, high-value functions. Our accelerators for Unity Catalog setup, automated data quality frameworks, and FinOps dashboards provide immediate control over your data and costs, ensuring your platform is both powerful and efficient from day one.

Databricks-Native Optimization
Leveraging Platform-Specific Capabilities
Our platform implementations are optimized specifically for Databricks, leveraging advanced features like the Photon engine, serverless compute, and Delta Lake liquid clustering. We ensure maximum performance and cost efficiency through platform-native capabilities that lower your TCO.
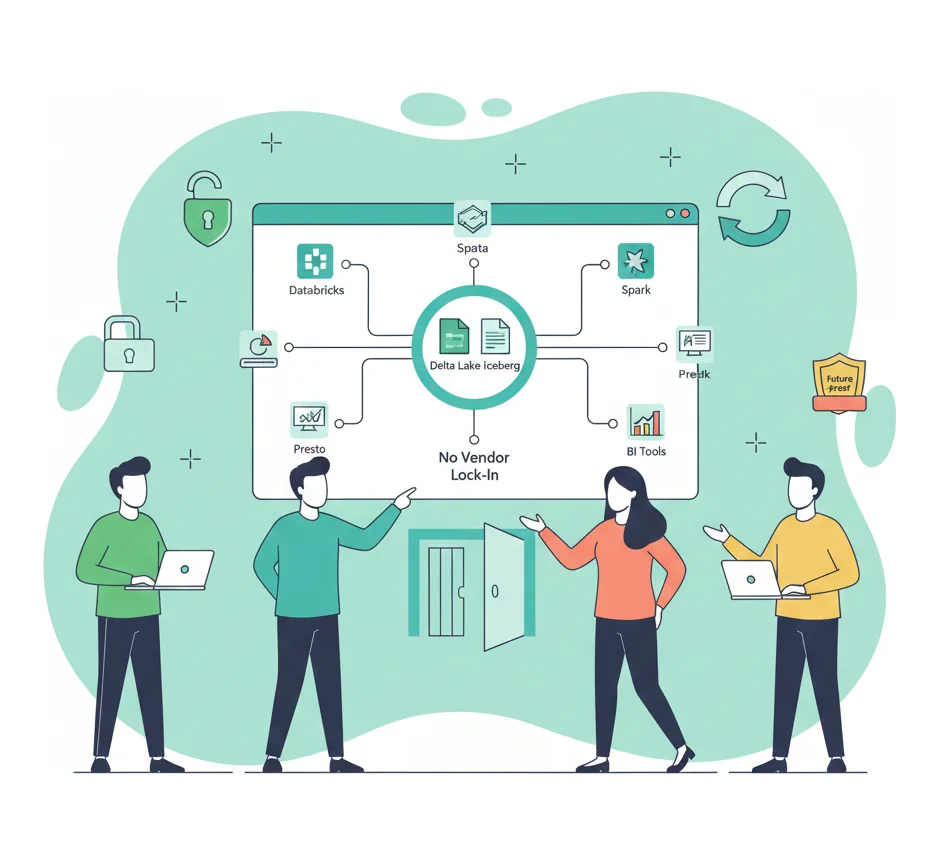
Open Lakehouse Foundation
Future-Proof and Interoperable by Design
We build on open formats like Delta Lake and Apache Iceberg, ensuring your data platform is vendor-agnostic and future-proof. This approach enables interoperability with other tools while maximizing the performance benefits of the Databricks Data Intelligence Platform.
Why Choose Dhristhi?

Deep Databricks Expertise
Our team has extensive experience with the Databricks Data Intelligence Platform, Unity Catalog, and advanced lakehouse architectures. We understand the nuances of Delta Lake optimization, serverless compute, and have implemented platforms that scale from startup to enterprise workloads.

Focus on Business Outcomes
We are your partners in value creation. We work with you to define and track key performance indicators that measure the success of your data platform, ensuring our technical solutions deliver concrete, measurable business outcomes and a clear return on investment.

Speed to Value with Accelerators
We don’t just build platforms; we accelerate your time-to-value. Our proven frameworks and pre-built accelerators for automated governance and FinOps are based on best practices from dozens of successful implementations, giving you a head start on platform maturity and ROI.
Get Started with Us
Ready to turn your data into a competitive advantage? Start Your Assessment to see how we can deliver your AI-ready data platform in 60 days.
Ready to take your business to the next level?
Contact Us
Feel free to use the form or drop us an email.


